Publications
Full list of research papers, preprints, and publications
2026
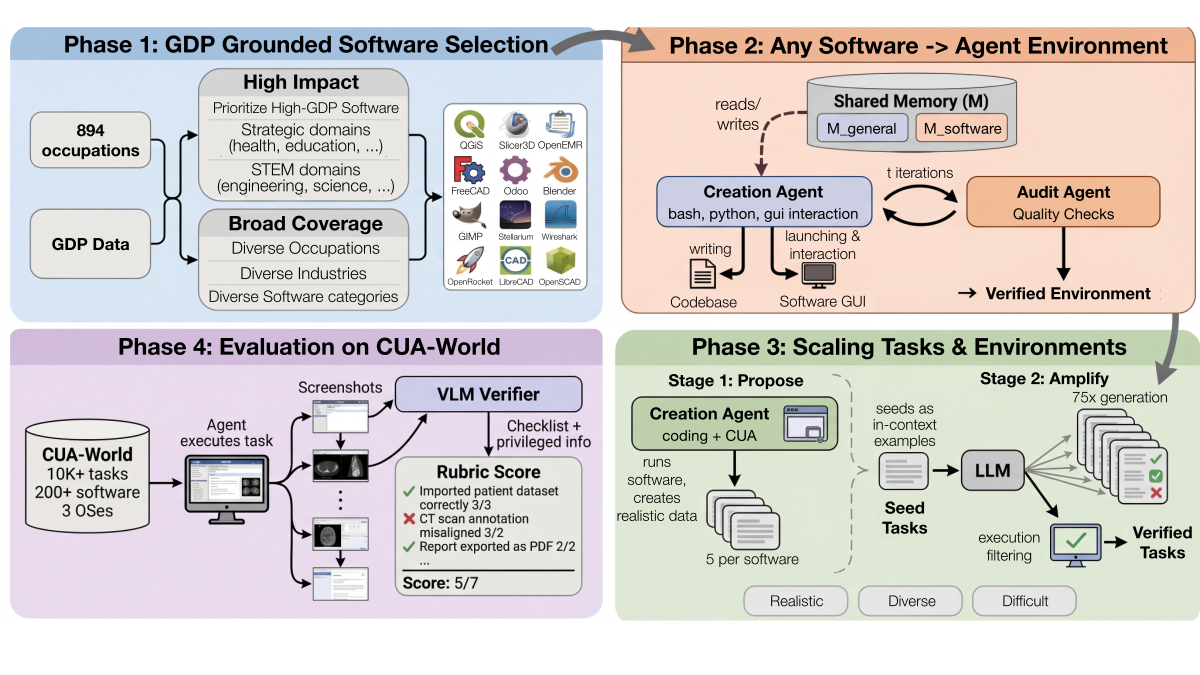
Gym-Anything: Turn Any Software into an Agent Environment
Pranjal Aggarwal, Graham Neubig, Sean Welleck
We introduce Gym-Anything, a framework that turns any software into a computer-use agent environment with a simple make() call. The system includes 200+ real-world applications across 22 occupational categories, generating 10,000+ tasks with checklist-based verification. We also introduce CUA-World-Long, a benchmark of 200 long-horizon tasks evaluating agents on 500+ step interactions.
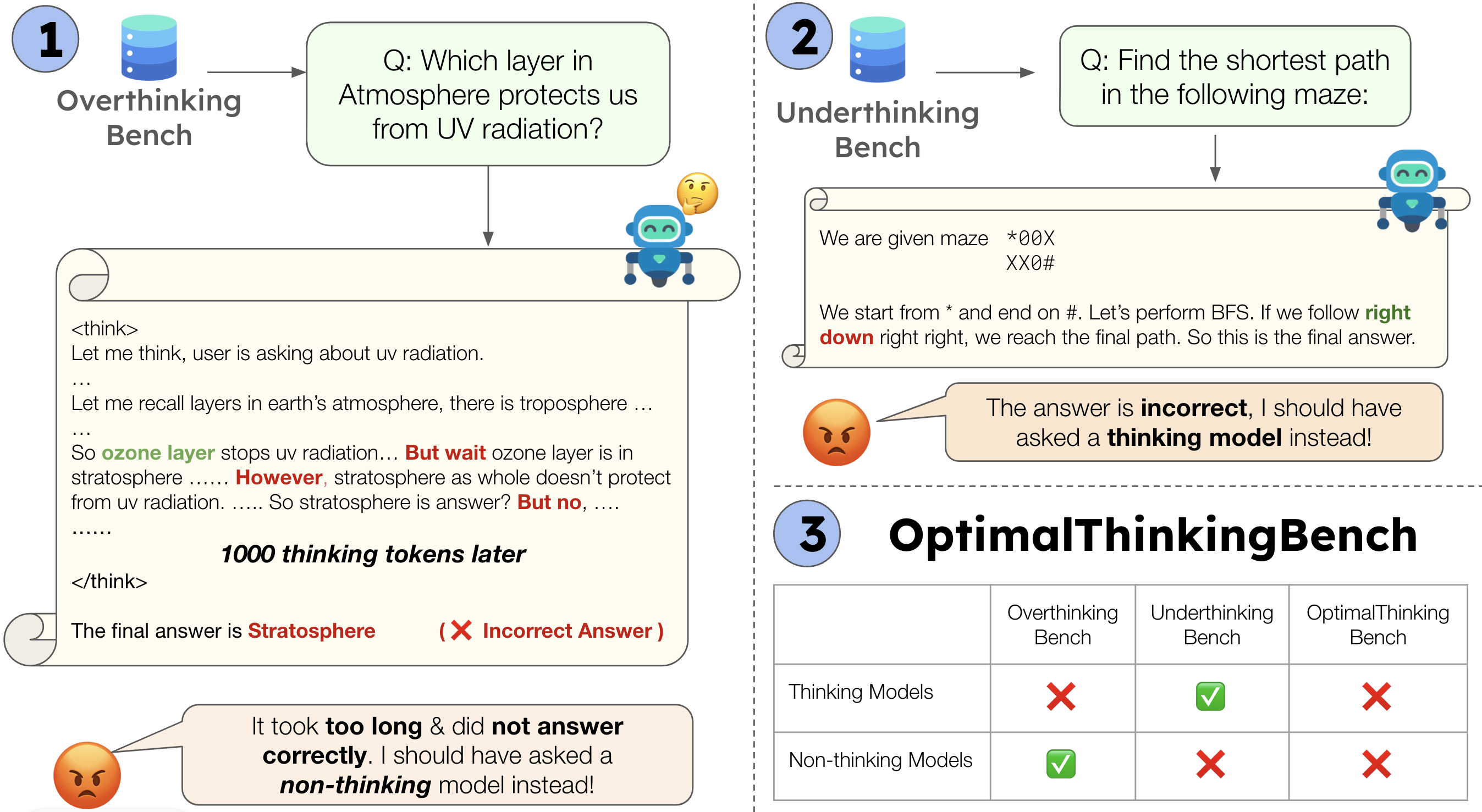
OptimalThinkingBench: Evaluating Over and Underthinking in LLMs
Pranjal Aggarwal, Seungone Kim, Jack Lanchantin, Sean Welleck, Jason Weston, Ilia Kulikov, Swarnadeep Saha
Thinking LLMs solve complex tasks at the expense of increased compute and overthinking on simpler problems, while non-thinking LLMs are faster and cheaper but underthink on harder reasoning problems. We introduce OptimalThinkingBench, a unified benchmark that jointly evaluates overthinking and underthinking in LLMs and also encourages the development of optimally-thinking models that balance performance and efficiency. Our benchmark comprises two sub-benchmarks: OverthinkingBench, featuring simple math and general queries in 72 domains, and UnderthinkingBench, containing 11 challenging reasoning tasks along with harder math problems. Using novel thinking-adjusted accuracy metrics, we extensively evaluate 33 different thinking and non-thinking models and show that no model is able to optimally think on our benchmark.
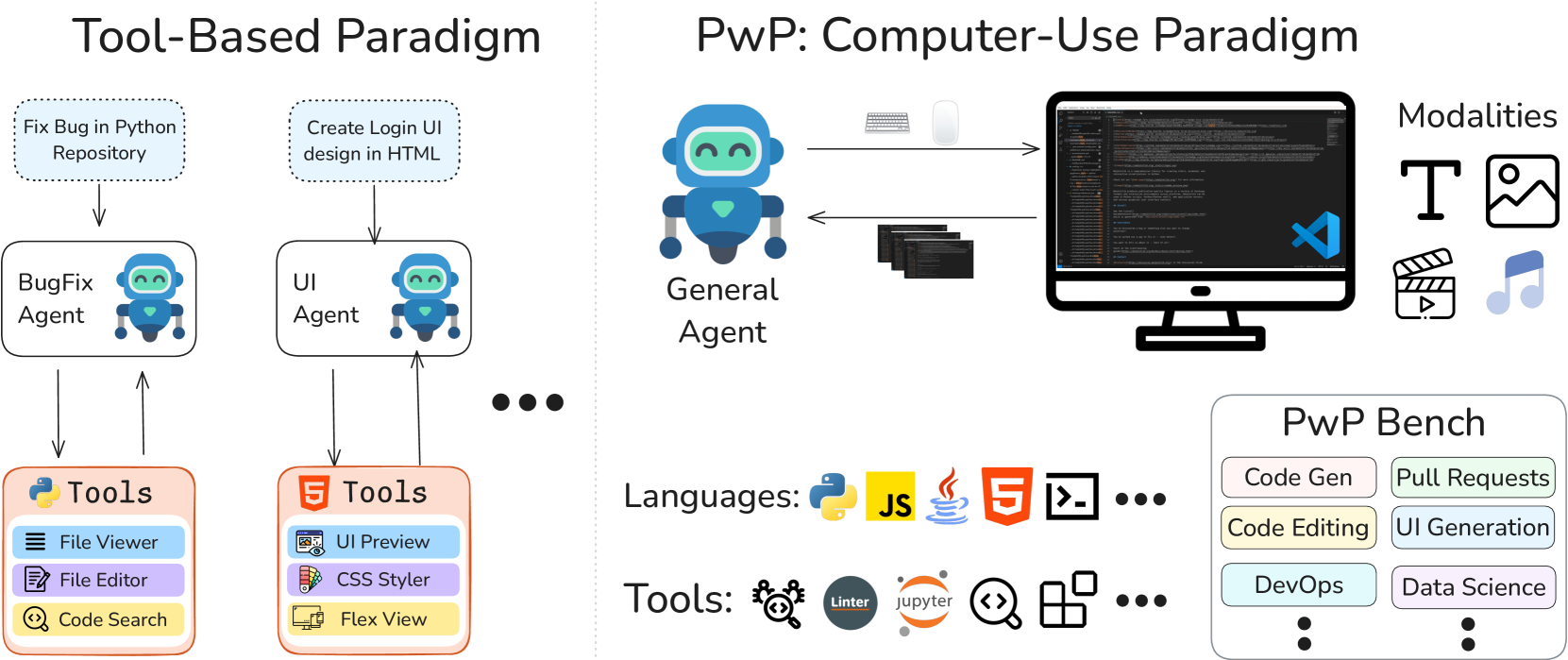
Programming with Pixels: Computer-Use Meets Software Engineering
Pranjal Aggarwal, Sean Welleck
Computer-use agents (CUAs) hold the promise of performing a wide variety of general tasks, but current evaluations have primarily focused on simple scenarios. We introduce Programming with Pixels (PwP), the first comprehensive computer-use environment for software engineering, where agents visually control an IDE to perform diverse software engineering tasks. We introduce PwP-Bench, a benchmark of 15 existing and new software-engineering tasks spanning multiple modalities, programming languages, and skillsets. We find that when interacting purely visually, CUAs perform significantly worse than specialized coding agents. However, when given direct access to just two APIs -- file editing and bash operations -- performance jumps, often reaching the levels of specialized agents despite having a task-agnostic design.

Reasoning Over Mathematical Objects: On-Policy Reward Modeling and Test Time Aggregation
Pranjal Aggarwal, Marjan Ghazvininejad, Seungone Kim, Ilia Kulikov, Jack Lanchantin, Xian Li, Tianjian Li, Bo Liu, Graham Neubig, Anaelia Ovalle, Swarnadeep Saha, Sainbayar Sukhbaatar, Sean Welleck, Jason Weston, Chenxi Whitehouse, Adina Williams, Jing Xu, Ping Yu, Weizhe Yuan, Jingyu Zhang, Wenting Zhao
The ability to precisely derive mathematical objects is a core requirement for downstream STEM applications, including mathematics, physics, and chemistry. Yet, current LM evaluations of mathematical and scientific reasoning rely heavily on simplified answer formats. In this paper we provide three contributions: (i) we build and release training data and benchmarks for deriving mathematical objects, the Principia suite; (ii) we provide training recipes with strong LLM-judges and verifiers, where we show that on-policy judge training boosts performance; (iii) we show how on-policy training can also be used to scale test-time compute via aggregation. We find that strong LMs such as Qwen3-235B and o3 struggle on Principia, while our training recipes can bring significant improvements over different LLM backbones.

Image Editing Software as a Tool: MLLM Agents for Precise Image Editing via API-Driven Control
Maxwell Jones, Pranjal Aggarwal, Lawrence Keunho Jang, Trung Bui, Franck Dernoncourt, Gang Wu, Jun-Yan Zhu, Ruslan Salakhutdinov
We explore the use of multimodal large language model (MLLM) agents for precise image editing through API-driven control of professional image editing software, enabling complex editing operations that go beyond the capabilities of end-to-end generative models.
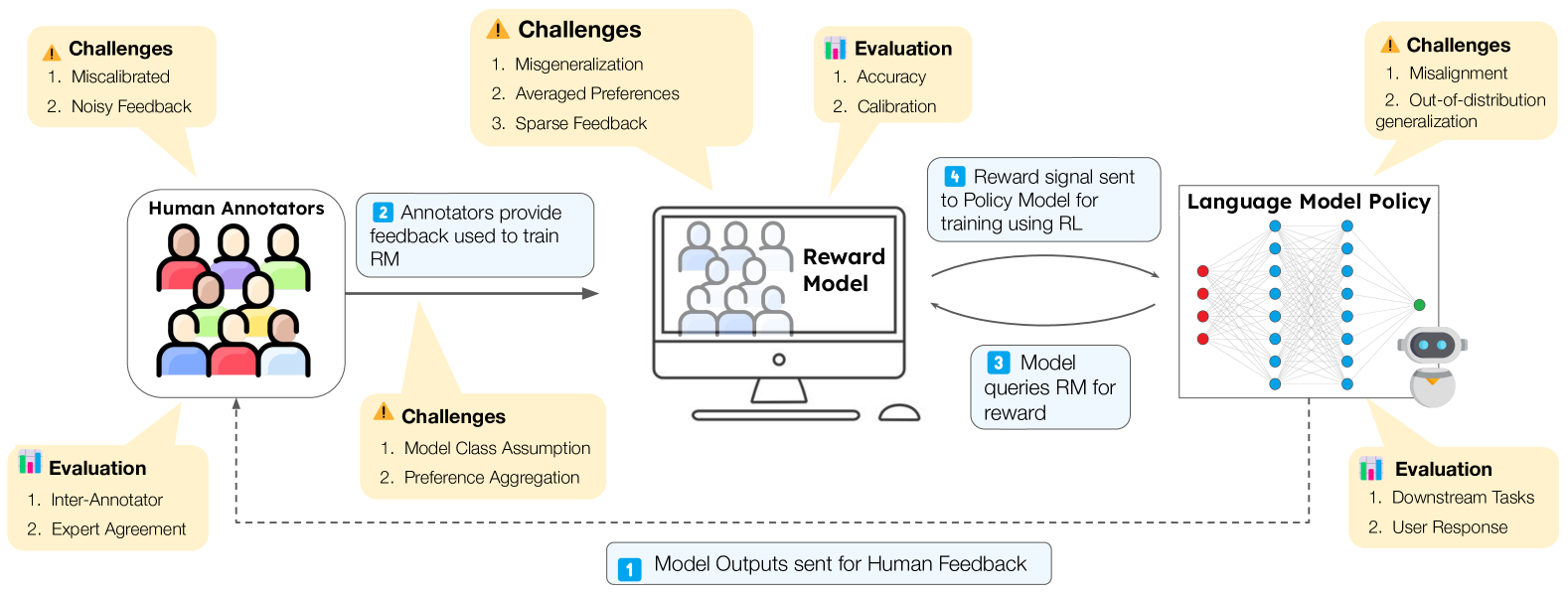
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari*, Pranjal Aggarwal*, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
This paper analyzes RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component -- the reward model. We characterize limitations including incorrect generalization, model misspecification, and sparsity of feedback. We provide a comprehensive survey covering reward model training, policy optimization, and emerging approaches, offering a unified framework for understanding the rapidly evolving RLHF landscape.
2025
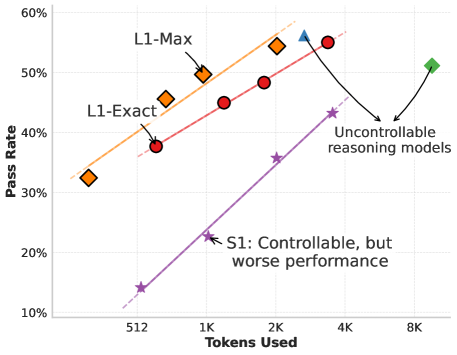
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
Pranjal Aggarwal, Sean Welleck
We present L1, a method for controlling the inference-time compute of reasoning models through reinforcement learning. L1 enables models to adaptively allocate thinking time based on problem difficulty, improving efficiency without sacrificing accuracy.
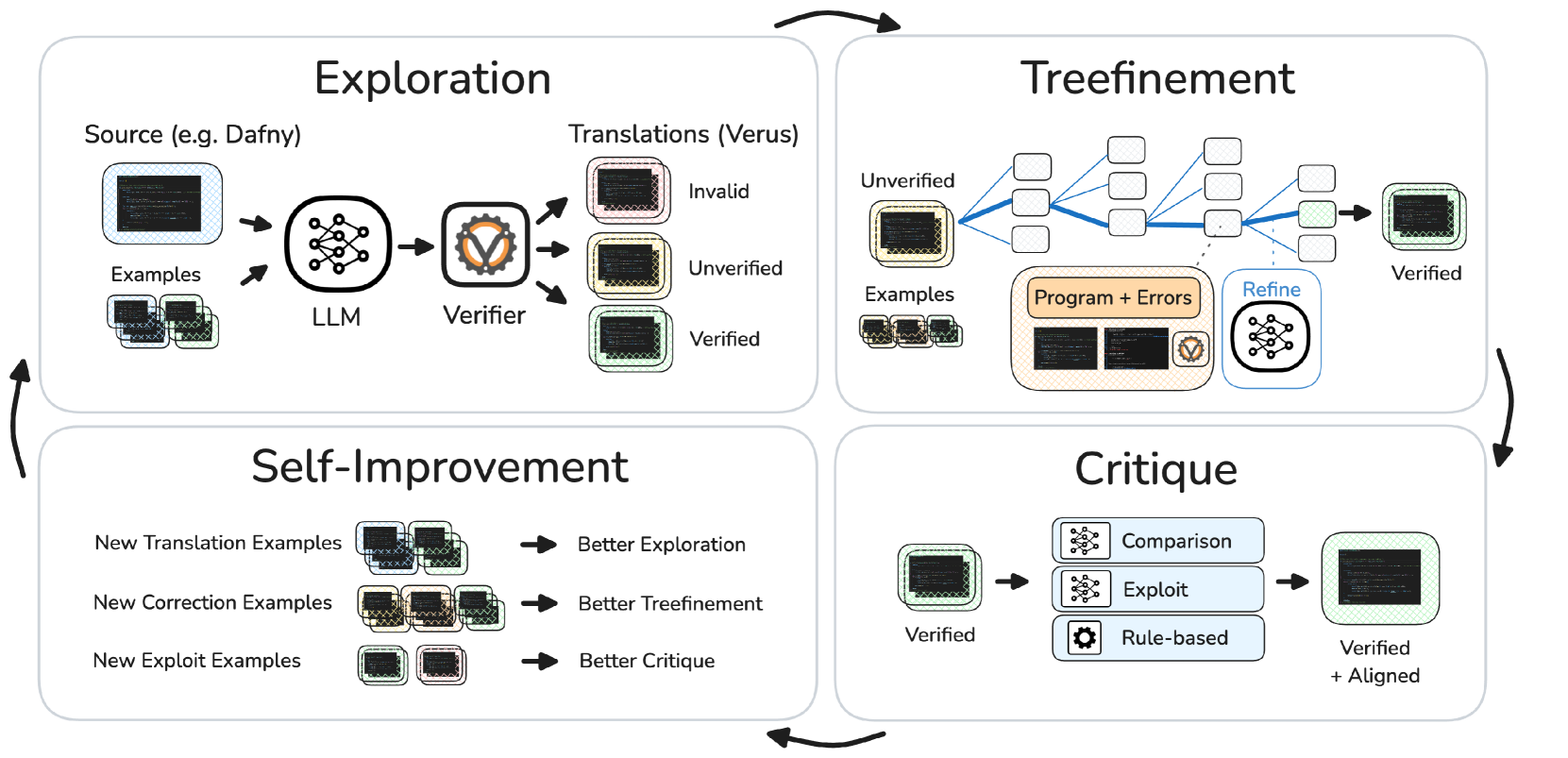
AlphaVerus: Bootstrapping Formally Verified Code Generation through Self-Improving Translation and Treefinement
Pranjal Aggarwal, Bryan Parno, Sean Welleck
We introduce AlphaVerus, a system that bootstraps formally verified code generation through iterative self-improvement. AlphaVerus combines translation from natural language to verified code with tree-based refinement strategies.
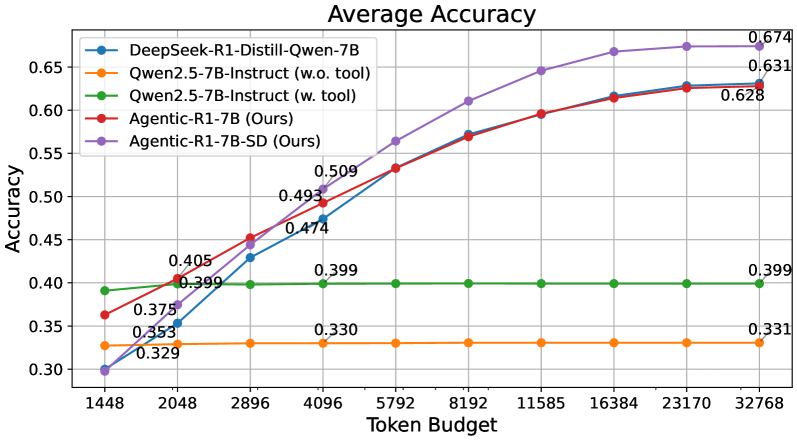
Agentic-R1: Distilled Dual-Strategy Reasoning
Weihua Du, Pranjal Aggarwal, Sean Welleck, Yiming Yang
Current long chain-of-thought (long-CoT) models excel at mathematical reasoning but rely on slow and error-prone natural language traces. Tool-augmented agents address arithmetic via code execution, but often falter on complex logical tasks. We introduce DualDistill, a fine-tuning framework that distills complementary reasoning strategies from multiple teachers into a unified student model. Using this approach, we train Agentic-R1, which dynamically selects the optimal strategy for each query, invoking tools for arithmetic and algorithmic problems, and using text-based reasoning for abstract ones.
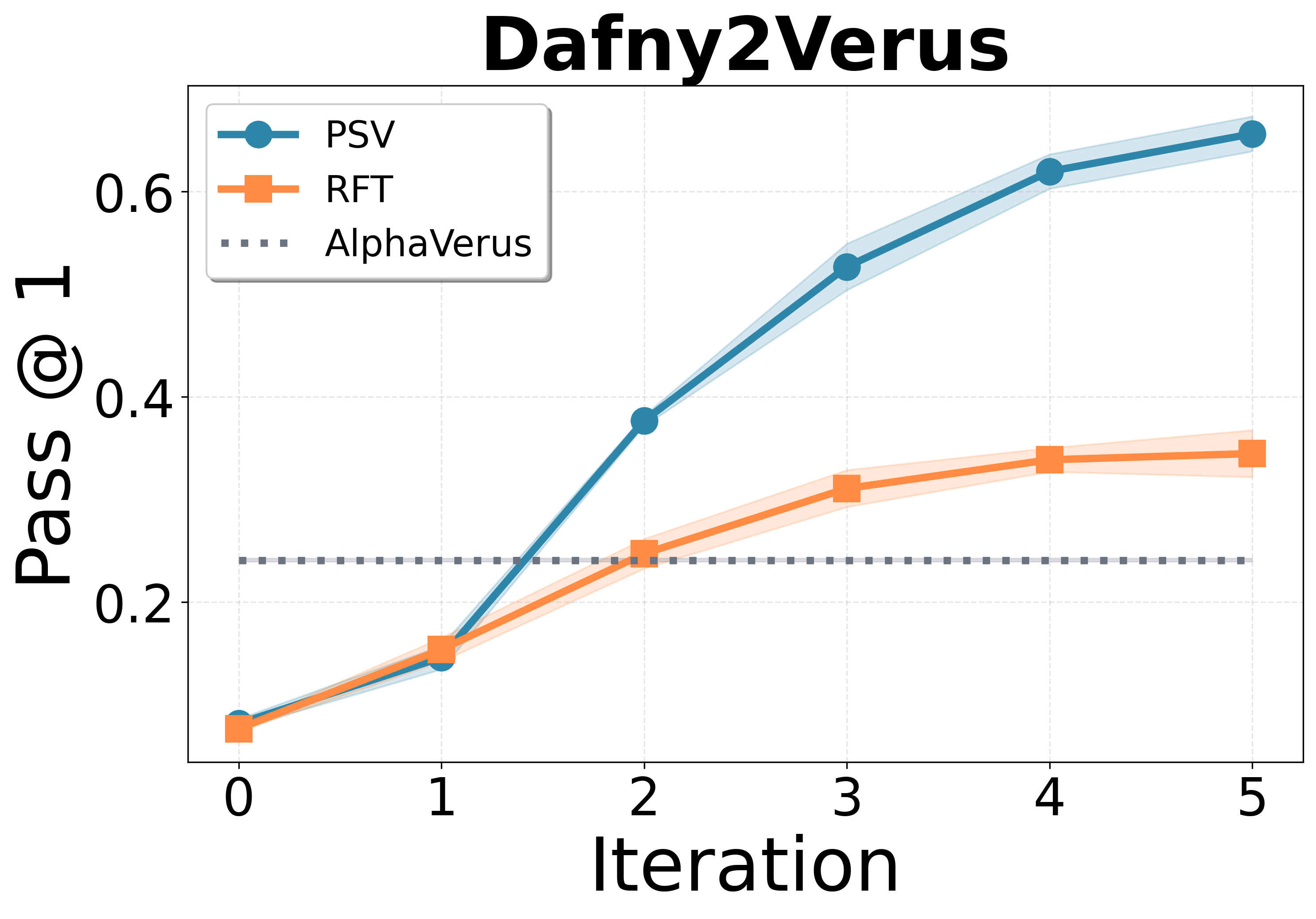
Propose, Solve, Verify: Self-Play Through Formal Verification
Alex Wilf, Pranjal Aggarwal, Bryan Parno, Daniel Fried, Louis-Philippe Morency, Paul Pu Liang, Sean Welleck
We study self-play in the verified code generation setting, where formal verification provides reliable correctness signals. We introduce Propose, Solve, Verify (PSV), a simple self-play framework where formal verification signals are used to create a proposer capable of generating challenging synthetic problems and a solver trained via expert iteration. We use PSV to train PSV-Verus, which across three benchmarks improves pass@1 by up to 9.6x over inference-only and expert-iteration baselines.

The Majority is not always right: RL training for solution aggregation
Wenting Zhao, Pranjal Aggarwal, Swarnadeep Saha, Asli Celikyilmaz, Jason Weston, Ilia Kulikov
We propose to learn aggregation as an explicit reasoning skill: given a set of candidate solutions, we train an aggregator model to review, reconcile, and synthesize a final, correct answer using reinforcement learning from verifiable rewards. A key ingredient is careful balancing of easy and hard training examples. Empirically, our method AggLM outperforms both strong rule-based and reward-model baselines across multiple benchmarks, and generalizes effectively to solutions from differing models.
2024
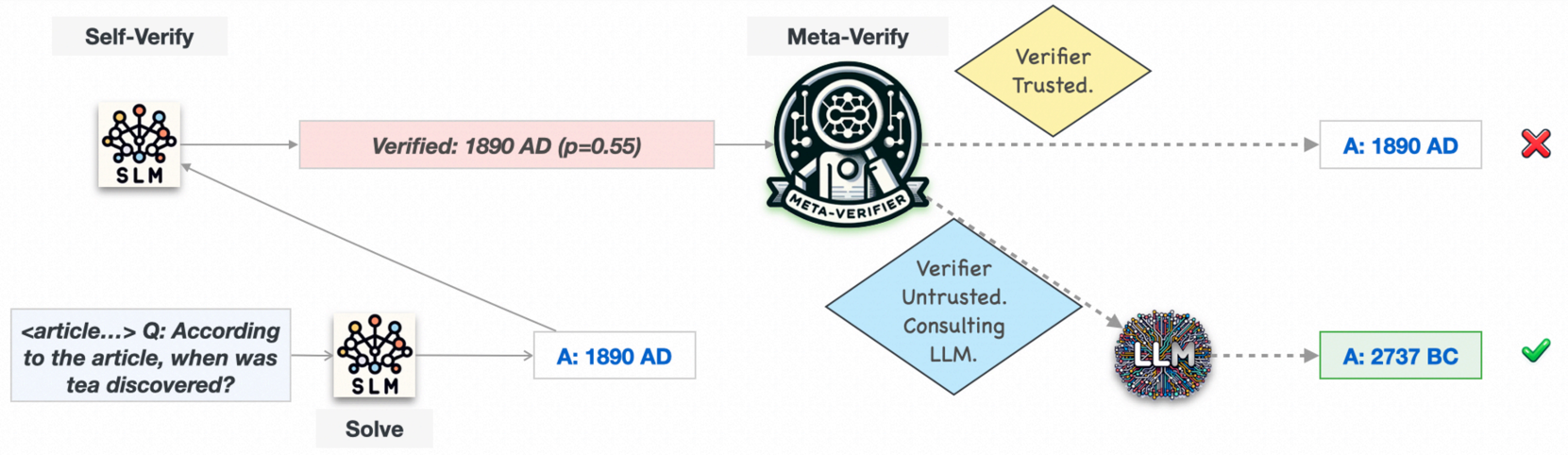
AutoMix: Automatically Mixing Language Models
Pranjal Aggarwal*, Aman Madaan*, Ankit Anand, Srividya Pranavi Potharaju, Swaroop Mishra, Pei Zhou, Aditya Gupta, Dheeraj Rajagopal, Karthik Kappaganthu, Yiming Yang, Shyam Upadhyay, Mausam, Manaal Faruqui
Large language models (LLMs) are now available from cloud API providers in various sizes and configurations. We present AutoMix, an approach that strategically routes queries to larger LMs based on the approximate correctness of outputs from a smaller LM. AutoMix employs a few-shot self-verification mechanism and a POMDP-based router, reducing computational cost by over 50% for comparable performance.
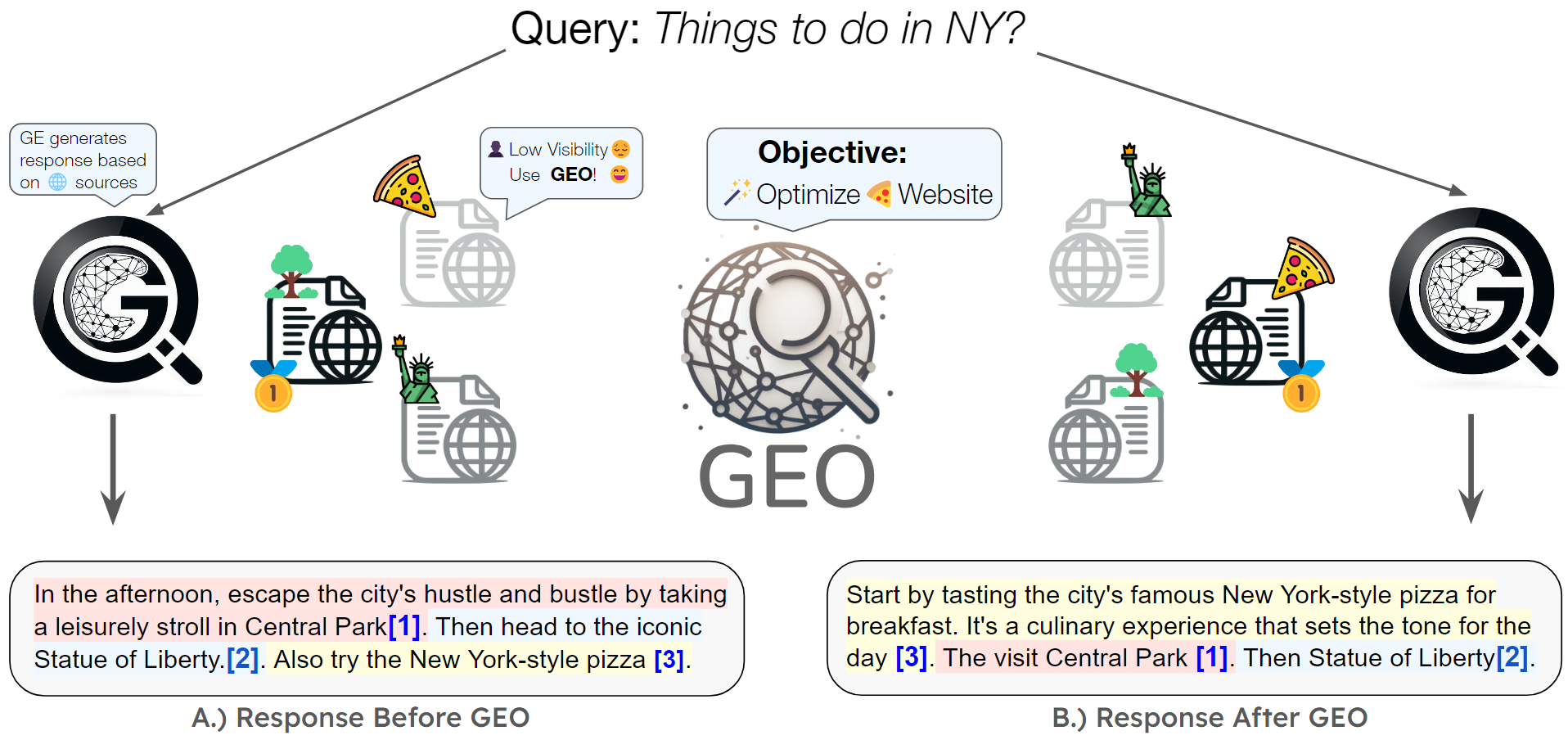
GEO: Generative Engine Optimization
Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande
The advent of large language models has ushered in a new paradigm of search engines that use generative models to gather and summarize information. We introduce Generative Engine Optimization (GEO), the first novel paradigm to aid content creators in improving their content visibility in generative engine responses. GEO can boost visibility by up to 40%.
2023
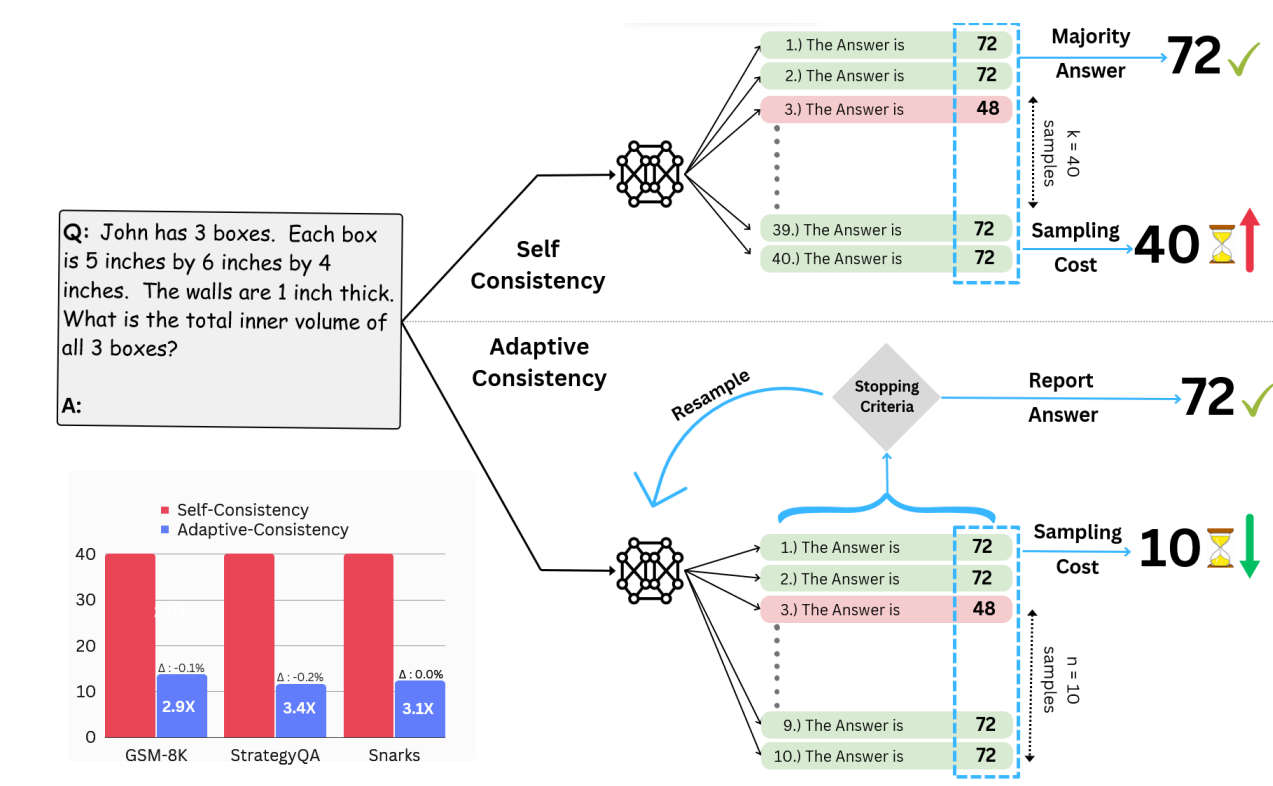
Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLMs
Pranjal Aggarwal, Aman Madaan, Yiming Yang, Mausam
We introduce Adaptive-Consistency, a method that dynamically adjusts the number of samples based on the model's confidence, significantly reducing computational costs while maintaining accuracy for reasoning and coding tasks.
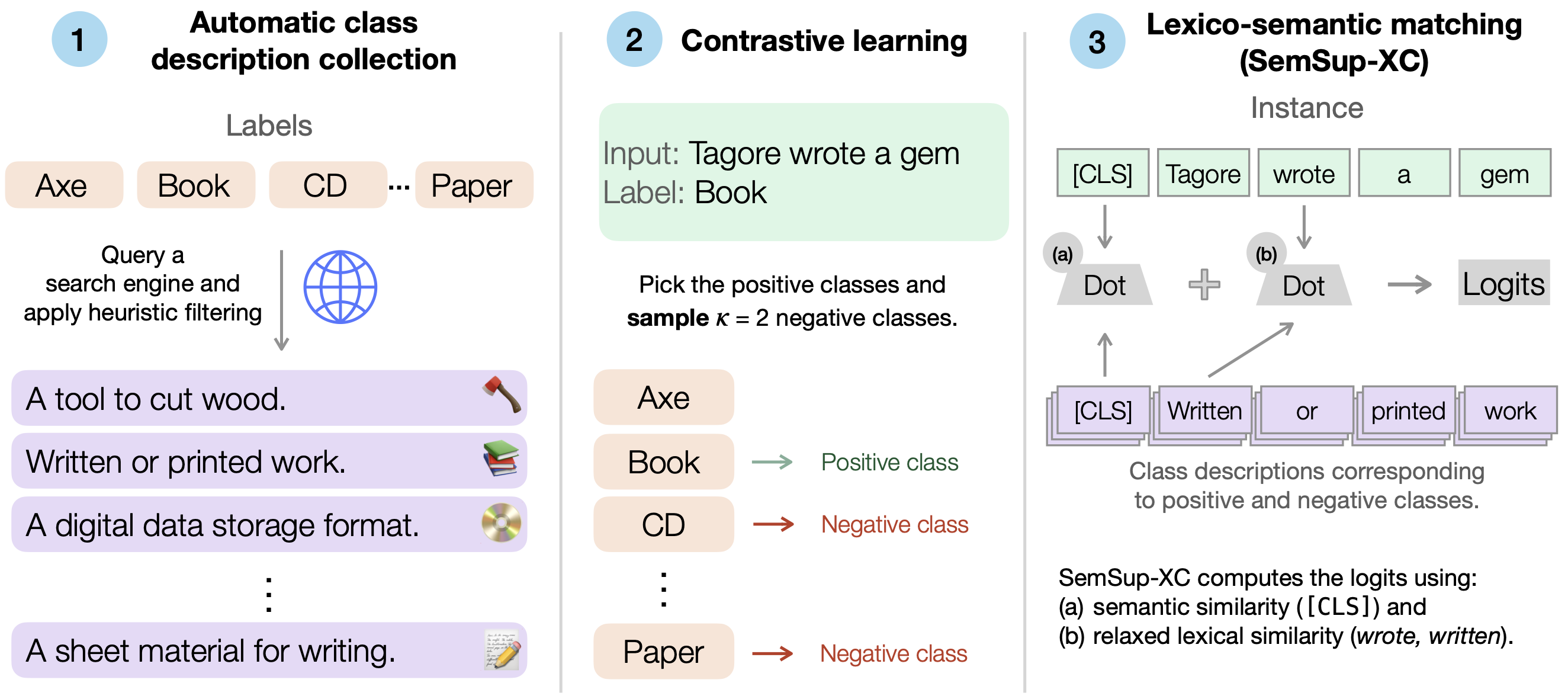
SemSup-XC: Semantic Supervision for Zero and Few-Shot Extreme Classification
Pranjal Aggarwal, Ameet Deshpande, Karthik Narasimhan
We introduce SemSup-XC, a method that leverages semantic supervision for zero and few-shot extreme classification. Our approach significantly outperforms existing baselines by utilizing rich semantic representations of labels.
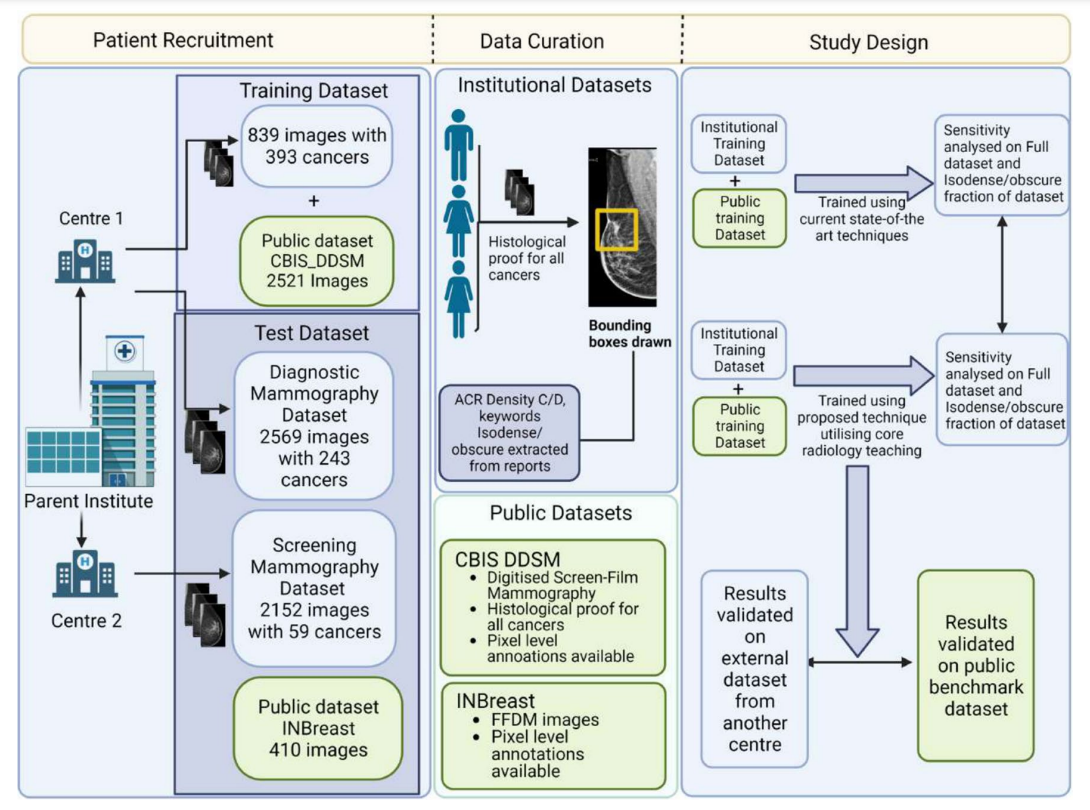
Deep Learning for Detection of Iso-Dense, Obscure Masses in Mammographically Dense Breasts
Pranjal Aggarwal*, Krithika Rangarajan*, Dhruv Kumar Gupta, Rohan Raju Dhanakshirur, Akhil Baby, Chandan Pal, Arunkumar Gupta, Smriti Hari, Subhashis Banerjee, Chetan Arora
We present a deep learning model for improving cancer detection in mammographically dense breasts. Our three-pronged approach explicitly trains the network to recognize features like spiculations and architectural distortion, utilizes opposite breast comparison for asymmetry detection, and enhances images through piecewise-linear transformation. Results show sensitivity improvements across multiple datasets, with isodense/obscure cancer detection improving from 74.6% to 85.3%.